I just spent more than two hours troubleshooting a seemingly simple HTML problem. When I copied and pasted a small section of HTML, the web browser displayed the newly-pasted section differently from the original. The horizontal spacing between some of the elements was slightly different, causing the whole page to look wrong. But how could this be? The two HTML sections were identical – the new one was literally a copy of the old one.
This simple-sounding problem defied all my attempts to explain it. I came up with lots of great theories: problems with my CSS classes, or with margins and padding. Mismatched HTML tags. Browser bugs. I tried three different browsers and got the same results in all of them.
Feeling very confused, I looked again at the two sections of HTML in the WordPress editor (text view), and confirmed they were exactly identical. Then I tried Firefox’s built-in web developer tools to view the page’s rendered elements, and compared all their CSS properties. Identical – yet somehow they rendered differently. I used the developer tools to examine the exact HTML received from my web server, checked the two sections again, and verified they were character-for-character identical. Firefox’s “page source” tool also confirmed the two sections were exactly identical.
By this point I was getting ready to blame cosmic rays or voodoo magic. I discovered that any time I copy-pasted any similar HTML section, the newly-pasted section would appear in the browser with the wrong element spacing. How could this possibly be? I then tried the W3C Validator, which found some other problems with my page, but nothing that could explain this behavior. And once again, it confirmed that despite rendering differently in the browser, the two sections of HTML were identical.
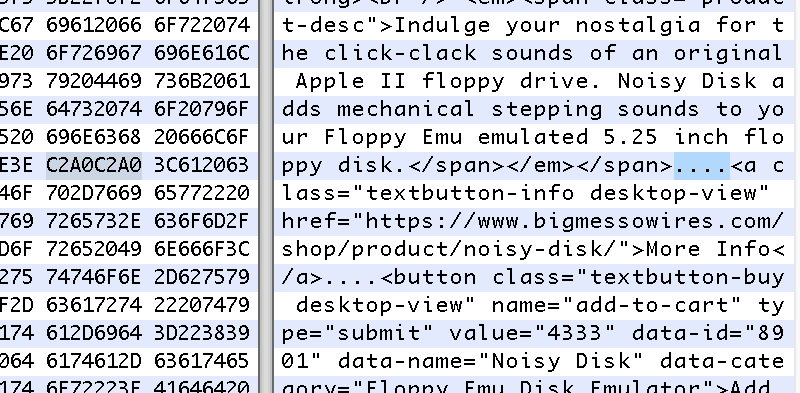
Clearly something wasn’t adding up. I used curl to download the web page from my web server, viewed the local copy, and saw the same behavior as before. But when I opened the stored .html document with a hex editor, I finally had my answer. The two sections of HTML were not identical: one section used a different type of space character from the other.
What the hell.
I discovered that the original HTML section contained non-breaking spaces. But instead of encoding them with the entity, they were encoded directly as Unicode character C2A0. I’m not sure when or how this happened, but I blame WordPress. When viewing this section in the WordPress HTML editor, the C2A0 spaces appeared like normal spaces, and copy-pasting the section inside the editor silently converted non-breaking spaces to normal spaces with hex value 20. So the copied version rendered differently, even though the source HTML appeared to be the same.
This is like the 21st century version of confusing a zero with a capital letter O, yet worse. I wasn’t even aware that non-breaking spaces have a Unicode character value – I thought was the only way to encode them. I changed the HTML back to use and now it all works fine.
I’m surprised at how many different tools failed to reveal this subtle but important difference between types of spaces in the HTML source. The WordPress HTML editor failed to show or correctly handle the difference. The Firefox web developer tools and page source tools failed. The W3C Validator’s source view failed. Curl plus a hex editor was the only way to finally establish the ground truth about the precise contents of the HTML source.